
How To Backup Your SQL Databases Today!
Backup and Restore are critical concepts to understand when working with databases in SQL and SQL Server.
Whether you are new to SQL and/or SQL Server or an experienced database analyst, you never know when a disaster might occur.
It could be a hardware failure, a data source issue or something else which causes your system/application to crash.
It’s not unknown for something as simple as a SQL join to cause issues.
If it does so, you need to be confident that you can Backup and Restore your data. This is especially true if you are still learning SQL or MS SQL Server and so could make errors. If you need help learning these tools, backup is covered on our SQL courses.
“Backup is the backbone of your system”.
As a database administrator, you should routinely be taking a backup of your database.
That may be every month, every week, daily or hourly, depending on the importance of your data, the source data and the amount of work being carried out. This then allows you to restore a backup if disaster strikes.
For example, if you are managing a finance-related database, this is high-value data, and so a backup should be taken at least every 15 minutes and probably more frequently than that.
The backup process itself does not need to be onerous as it can be automated by scheduling them in a SQL Server agent job, but there are many different SQL Server backup types.
We discuss choosing the optimal SQL Server backups at the end of this article, as well as looking at a couple of useful tools to help you automate this process. SQL server backups are simple to automate.
While SQL server backups are simple to automate, as ever, it is important to understand a process before you automate it. It is also vital to test your SQL Server backups so that you know that your system works.
Once your Server is backed up properly, you can look into using its data permanently, such as by importing it for visualisation. Check our comprehensive guide on connecting PowerBI to SQL Server.
Types of Backups
There are a number of different types of SQL Server Backups :
- Full Database Backup
- Differential Backup
- Transaction Log Backup
- Filegroup Backup
- Partial Backup
Full, Differential and Transaction Log backups all perform critical roles in a disaster recovery scenario. Let’s look at each in turn.
Full Database Backup
This allows you to backup a full SQL Server database as it says! This includes part of the transaction log so that the full database can be recovered when it is restored.
A transaction log is a sequential record of all changes made to the database while the actual data is contained in a separate file.
Each database has at least one physical transaction log file (.LDF) and one datafile (.MDF). A full backup backs up both files: transaction log and datafile. In other words, they represent the complete database at the time the backup is finished.
- If you backup a full database, it requires a large amount of space because it contains a transaction log as well as the actual underlying data.
- Taking this backup on a regular basis is highly recommended.
- The file extension for this file containing the backup is .BAK
- This backup can be performed on any database. There are three different recovery models for a full backup: SIMPLE, FULL, BULK LOGGED.
SIMPLE:
With this recovery model, the transaction log will be automatically truncated or deleted when it runs a checkpoint runs or is executed.
With a SIMPLE recovery model, a full transaction log is not maintained. This allows you to restore your data to its most recent state, but because the transaction log is lost, you can not restore it to an earlier point in time.
FULL or BULK LOGGED:
With the FULL or BULK LOGGED recovery model of the database, transaction logs will be maintained, and log backups will be taken along with a whole database backup. Though we can manually truncate transaction logs using the database shrink option if we have a space issue, this is not recommended.
Following steps are performed by MS SQL server while taking a full backup. It
- Locks the database.
- Blocks all transactions.
- Places a mark in the transaction log.
- Releases the database lock.
- Extracts all pages in the data files and writes them to the backup file.
This backup can be performed in two different ways i.e. using the GUI or through a T-SQL Server script.
Full Backup with T-SQL Server script
You can run the below script to take a full backup of the “AdventureWorks” SQL Server database and sent the backup file to the specified path (‘C:\Backups\AdventureWorks.BAK’).
BACKUP DATABASE AdventureWorks
TO DISK ‘C:\Backups\AdventureWorks.BAK’
GO
Full Backup with GUI
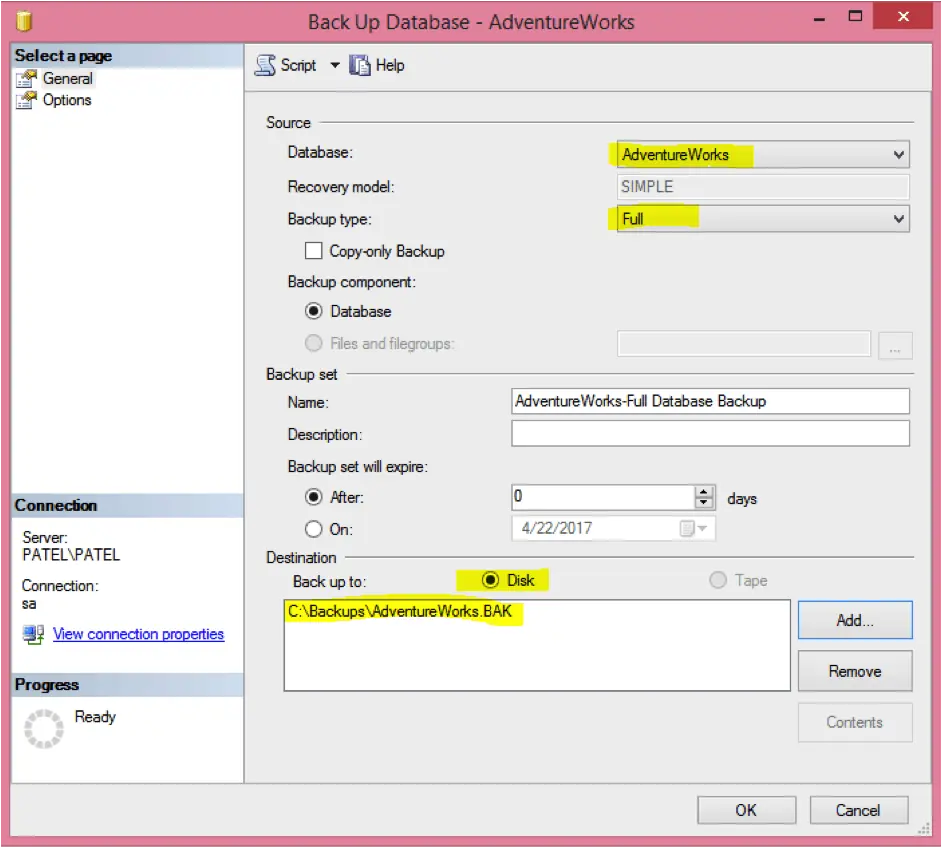
Using the GUI, you use the following steps to take a full backup of “AdventureWorks” SQL Server database and send the backup file to the specified path (‘C:\Backups\AdventureWorks.BAK’).
-
- Right click on the database name (“AdventureWorks”)
- Select Tasks > Backup
- Select “Full” as the backup type
- Select “Disk” as the destination
- Click on “Add…” to add a backup file and type “C:\Backups\AdventureWorks.BAK” and click “OK”
- Click “OK” again to create the backup
Differential Backup
A differential database backup is based on the most recent, previous full backup. A differential database backup only captures the data that has changed since the last full backup.
This means that if the last full backup was taken two days before, then you will find only the data that has changed in a differential backup. A previous full backup is needed if you want to restore a differential backup.
The primary purpose for creating differential backups is to reduce the number of log backups. This means that these backups take up less space than full backups. For this reason, it is standard practice to create a full backup less often than Differential backups.
Again a differential backup can also be performed with any of the three standard recovery models: SIMPLE, FULL or BULK LOGGED. They can be managed through a GUI or by using a T-SQL Server script.
The file extension of a for these backups files file is .DIF
Differential Backup with T-SQL Server script
The below script will take a differential backup using the “AdventureWorks” database.
BACKUP DATABASE AdventureWorks
TO DISK ‘C:\Backups\AdventureWorks.DIF’
WITH DIFFERENTIAL
GO
Differential Backup with GUI
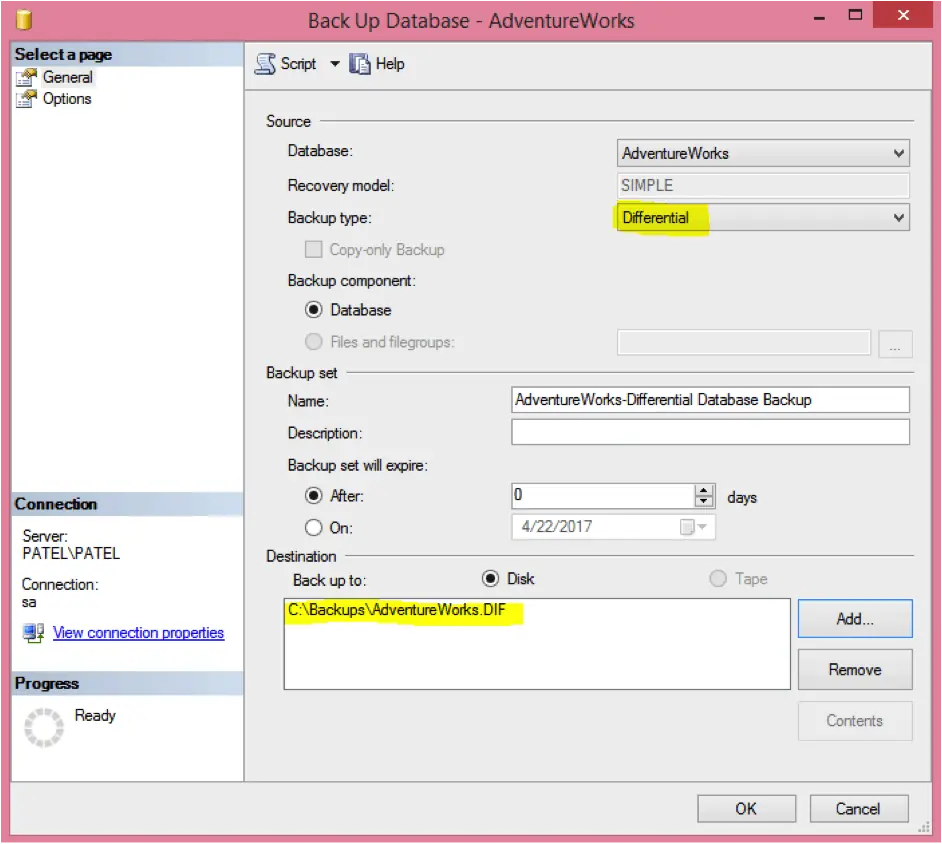
The below steps in a GUI will carry out a differential backup of the “AdventureWorks” database.
-
- Right click on the database name (“AdventureWorks”)
- Select Tasks > Backup
- Select “Differential” as the backup type
- Select “Disk” as the destination
- Click on “Add…” to add a backup file and type “C:\Backups\AdventureWorks.DIF” and click “OK”
- Click “OK” again to create the backup
Transaction Log Backup
A transaction log is a sequential record of all changes made to the database while the actual data is contained in a separate file. Every database has at least one physical transaction log file (.LDF) and one data file (.MDF).
A transaction log backs up ONLY the transaction log file (.LDF). Like a differential backup, a previous full backup is needed for restoring transaction log backups. Assuming that restoration is possible, it is possible to do ‘point in time recovery’ with the last transaction log backup.
From this, it is logical that a transaction log backup can not be carried out if the database is in SIMPLE mode. It only works with FULL or BULK LOGGED recovery models.
Whenever a change is made to a database, SQL Server logs that entry into the transaction log. Each entry has a unique number called an LSN (Log Sequence Number). Using this LSN, we can rewind the changes made to a database so that it is exactly as it was at that point in time. It is critical that the LSN sequence isn’t broken.
If it breaks, we will need to take a full backup before going back to transaction log backups. Otherwise, recovery will be impossible. LSN numbers start from 1 and keep increase with each change.
A transaction log backup occupies less space than a full or differential backup and so they can be taken more frequently. Transaction log backups are often carried out at very short intervals (Eg every 15 minutes).
The file extension of a transaction log backup file is .TRN
As mentioned above, you can not carry out transaction log backups on a database in SIMPLE recovery mode. If you need to change the recovery model of the database, you can run the below script to change the recovery model of the database from SIMPLE to FULL.
ALTER DATABASE AdventureWorks
SET RECOVERY FULL WITH NO_WAIT
GO
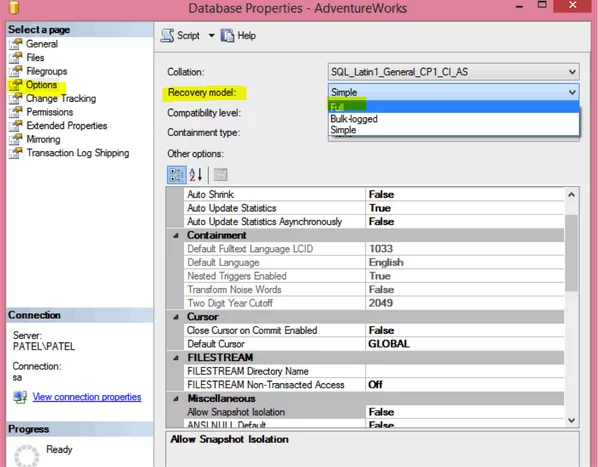
You can check the recovery model of the database from database properties.
- Right click on the database name (“AdventureWorks”)
- Select Properties
- Click on the Options tab
- Check the Recovery Model option.
- Change if recovery model is set to SIMPLE
Now you can perform a transaction log backup.
Transaction Log Backup with T-SQL Server script
You can run the below script to take a transaction log backup of “AdventureWorks” database.
BACKUP LOG AdventureWorks
TO DISK = ‘C:\Backups\AdventureWorks.TRN’
GO
Transaction Log Backup with GUI
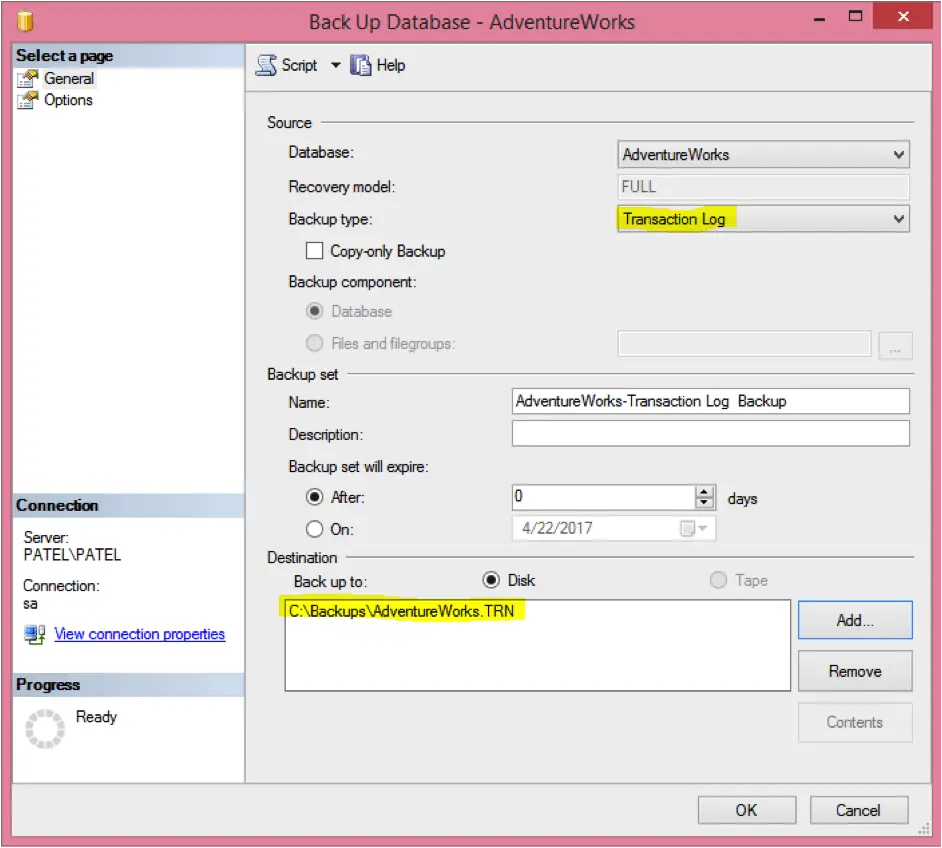
You can perform following steps to take a transactional backup of “AdventureWorks” database.
-
- Right click on the database name (“AdventureWorks”)
- Select Tasks > Backup
- Select “Transaction Log” as the backup type
- Select “Disk” as the destination
- Click on “Add…” to add a backup file and type “C:\Backups\AdventureWorks.TRN” and click “OK”
- Click “OK” again to create the backup
Filegroup Backup
A filegroup backup allows you to take a backup of all data files within a SQL server filegroup individually. The key difference between full database backups and filegroup backups is that you can take a backup of individual data files using a filegroup backup.
With a full database backup, you can only take a backup of a whole database. There is no option to take a backup of individual data files.
There are two primary reasons for creating multiple filegroups for data files: performance and recovery. Performance improves when you spread files across multiple disks because you have multiple heads reading and writing your data, rather than one doing all the work and often acting as a bottleneck.
If you want to know how to best organise your data, you can find out about each type of table in SQL with this guide.
Filegroups can be backed up and restored separately as well. This enables faster object recovery in the case of a disaster. It can also help the administration of bigger databases.
What is a Filegroup?
A filegroup is a logical structure to group objects in a database. For example, If you have a database with multiple tables, you can put these tables under separate filegroups (based on data within that tables) like all employee-related tables under one filegroup, order related tables under another filegroup and so on.
How to create a Filegroup?
By default, PRIMARY filegroup is created when you create a new database, and all data files are kept under that filegroup. You need to create additional filegroups if you want to split data files/tables. You can run the below script to add a new filegroup (Employees_FileGroup) to an existing database.
ALTER DATABASE AdventureWorks
ADD FILEGROUP Employees_FileGroup
You can find a newly added filegroup under Database properties.
Right click on a database name and select “Database Properties” to open the window below.
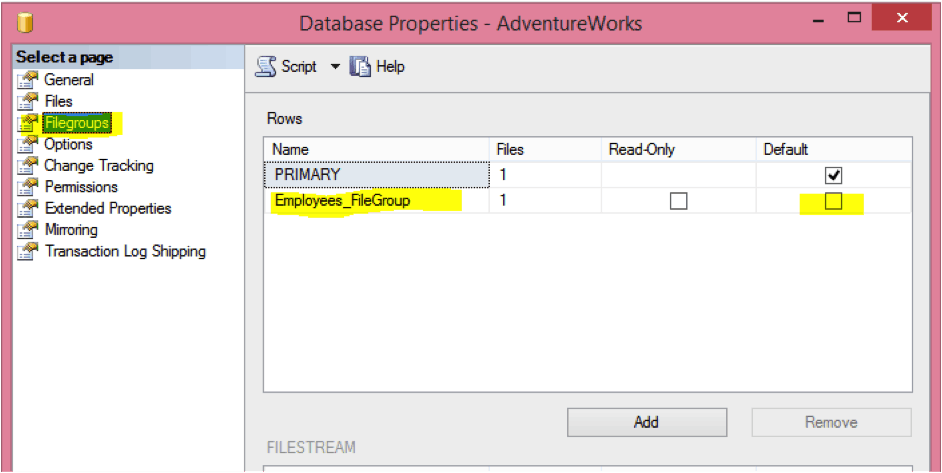
Now the next step is to create a new data file for the Employees_FileGroup Filegroup and assign the newly created data file to Employees_FileGroup. The script below will add a new data file (EmployeeData.mdf) to Employees_FileGroup
ALTER DATABASE AdventureWorks
ADD FILE
(NAME = EmployeeData,
FILENAME = ‘C:Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVERMSSQL\DATA\EmployeeData.mdf’)
TO FILEGROUP Employees_FileGroup
You can find a newly added data file under Database Properties > Files.
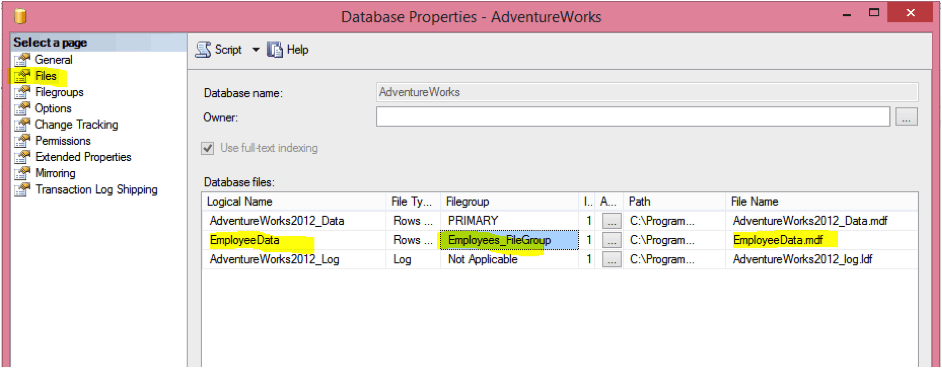
Now the next step is to create a new employee table and move it into the Employees_FileGroup. Note that the table must have a cluster index on it.
–Create Employee Information table
CREATE TABLE EmployeeInformation
(EmployeeId INT NOT NULL,
EmployeeName VARCHAR(250) NULL,
EmployeeAddress VARCHAR(250) NULL,
EmailId VARCHAR(150) NULL,
ContactNumber INT NULL)
–Create new clustered index on EmployeeId field of EmployeeInformation table and assign it to Employees_FileGroup
CREATE CLUSTERED INDEX CulsterIndex_EmployeeInformation
ON EmployeeInformation (EmployeeId)
ON Employees_FileGroup
Now that we have created a filegroup, let’s look at how we can take a backup of individual files or filegroups as well as all the files or filegroups in a database. Again we’ll look at doing this using the GUI or T-SQL Server directly.
Filegroup Backup with T-SQL Server
For the Employees_FileGroup, you can backup using the below script.
BACKUP DATABASE AdventureWorks
FILEGROUP = ‘Employees_FileGroup ‘
TO DISK = ‘C:\Backups\AdventureWorks_Employees_FileGroup.FLG’
Note: You can take a backup of all filegroups by not specifying FILEGROUP in the above query
Filegroup Backup with GUI
You can perform the following steps to take a backup of Employees_FileGroup. Note you can select multiple filegroups or all filegroups from the list (shown in the image below).
-
- Right click on the database name
- Select Tasks > Backup
- Select either “Full” or “Differential” as the backup type
- Select “Files and filegroups”
- Select the appropriate filegroup and click “OK”.
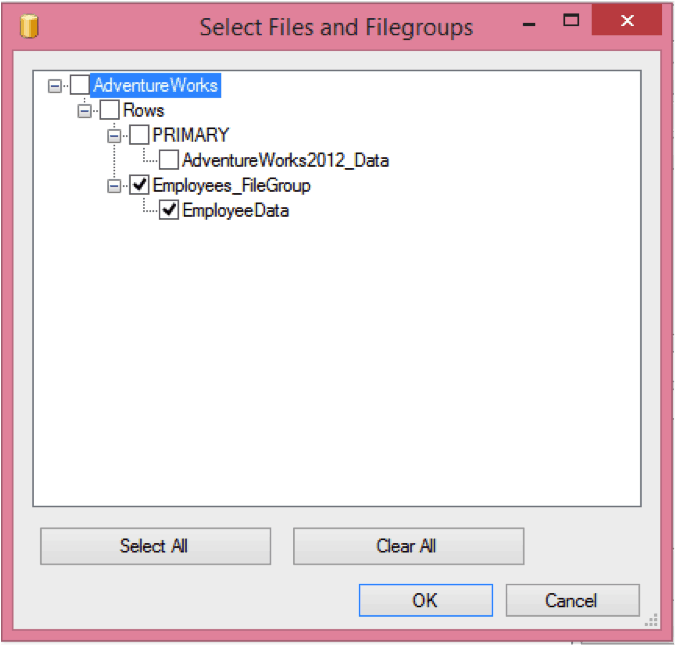
6. Select “Disk” as the destination
7. Click on “Add…” to add a backup file and path
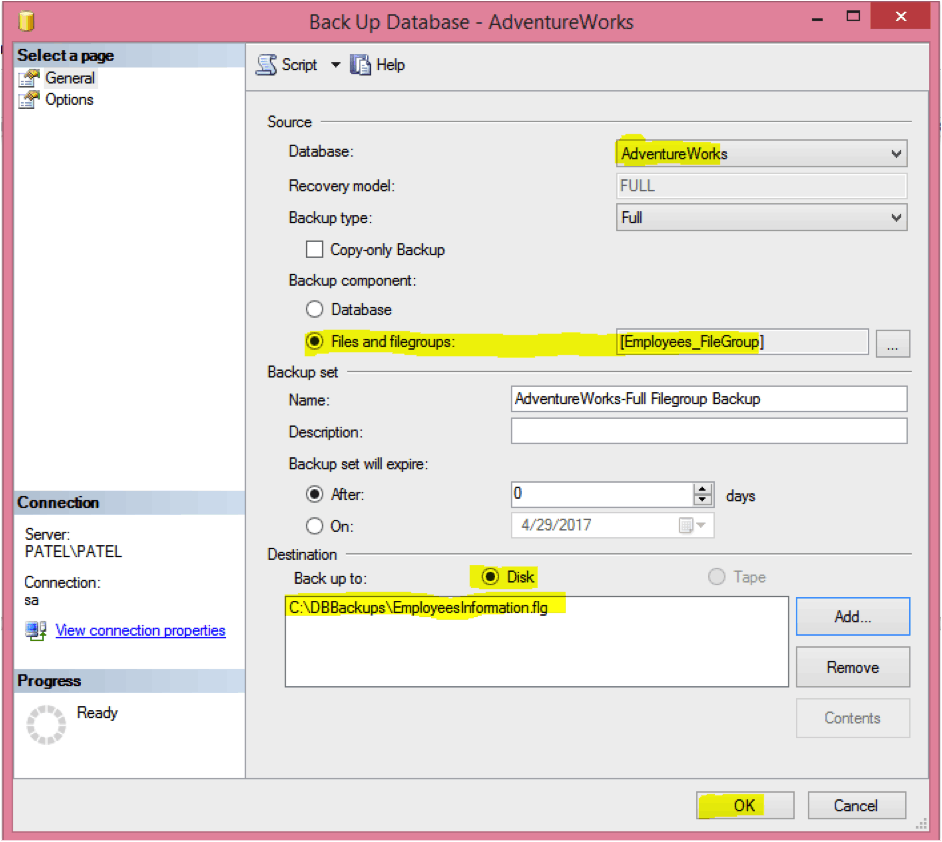
8. Click “OK” again to create the backup and repeat for other filegroups
Partial Backup
Partial backups are similar to file and filegroup backups. They allow us to back up only a subset of the data files that comprise a database.
However, whereas file and filegroup backups allow us to backup specific, individual files and filegroups, partial backups will make a backup copy of the primary filegroup and all read/write filegroups, omitting by default any filegroups designated as READONLY.
This means that partial backups are only relevant for databases that contain read-only filegroups; otherwise, a partial backup contains exactly the same data and objects as an equivalent full database backup.
Partial backups were designed to reduce the backup footprint of huge databases that contain a high proportion of read-only data. There is no need to back up the same data each night if we know that it can not have been changed since it is read-only.
Partial backups can be either FULL (with the file extension .BAK) or DIFFERENTIAL (with the file extension .DIF) as discussed above. They can not be used for a transaction log backup for obvious reasons.
The partial backup can only be carried out using T-SQL Server. There is no GUI option available for partial backup.
Full Partial Backup with T-SQL Server
BACKUP DATABASE AdventureWorks
READ_WRITE_FILEGROUPS
TO DISK = ‘C:\Backups\AdventureWorks_Partial.BAK’
GO
Differential Partial Backup with T-SQL Server
BACKUP DATABASE AdventureWorks
READ_WRITE_FILEGROUPS
TO DISK = ‘C:\AdventureWorks_Partial.DIF’
WITH DIFFERENTIAL
GO
Backup Strategy – Choosing The Optimal One
Choosing the optimal backup types is crucial for disaster recovery. The three key questions when defining a database backup plan are:
1. What is the importance of the data?
- Depending on the importance of data, you can define an optimal backup strategy. If you have finance or banking related data, no data loss can be tolerated.
- On the other hand, if you have some survey data or geographical data, some loss of data would be tolerated or may be easier for us to get them back from online sources.
- Hence if your data is crucial and you can not tolerate any loss of data, you should opt for a combination of all three SQL Server backup types (Full Backup + Differential Backup + Transactional Backup) as your strategy.
- If your data is not crucial and some data loss can be tolerated, then you can opt for full database backup at some specified interval like weekly or daily.
2. Can any data loss be tolerated?
- As we discussed in the previous point, if your data is crucial and no data loss is tolerated, you can opt for full + differential + transaction log backup. If some sort of data loss is tolerated, then you can opt for either full + differential or only full database backup. If you want to restore your database point in time, you should take a transactional backup and restore them.
3. How big is your database?
- Size also matters choosing an optimal backup process. If you have a small database, then you can take a full database backup periodically as there will be no space issue for small databases.
- If you have a medium-sized database, you can take full + differential backups.
- For larger databases, you should take more transaction and differential backups than full database backups; otherwise, you will face space issues.
Once we have these answers, it is easy to define a strategy.
Full Backup Only
- Use if the database is relatively small and if some data loss can be tolerated.
Full + Differential Backup
- Use for medium or large databases with low transaction densities where some loss of data can be tolerated.
Full + Differential + Transaction Log Backup
- Use for large databases with high transaction density where no data loss can be tolerated.
Always remember that you must follow the following backup sequence.
Full Backup → Differential Backup → Transaction Log Backup
Related Articles
Using Union Queries and Select Statements
Backup Strategies For SQL Databases
Appendix: SQL Server Backup Tools Acuity Training Uses
SQLBackupandFTP: Fantastic tool at affordable prices. All you need to do it fill in a single form, and the entire backup process will be automated – easy to use and appropriate flexible pricing based on your needs.
SQL SMS: Fantastic tool for managing SQL Server and database, created by Microsoft. SQL Server Management Studio Provides tools to configure, monitor and administer SQL Server and database instances.

- Facebook: https://www.facebook.com/profile.php?id=100066814899655
- X (Twitter): https://twitter.com/AcuityTraining
- LinkedIn: https://www.linkedin.com/company/acuity-training/